Interview with Keith Stanovich (2016)
The Rationality Quotient - Progress toward measuring rationality
By Coert Visser

What were your aims in making this test and how you will know whether you will have achieved those aims?
In our society, what gets measured gets valued. Our aim in developing the Comprehensive Assessment of Rational Thinking (the CART) was to draw attention to the skills of rational thought by measuring them systematically. In the book, we are careful to point out that we operationalized the construct of rational thinking without making reference to any other construct in psychology, most notably intelligence. Thus, we are not trying to make a better intelligence test. Nor are we trying to make a test with incremental validity over and above IQ tests. Instead, are trying to show how one would go about measuring rational thinking as a psychological construct in its own right. We wish to accentuate the importance of a domain of thinking that has been obscured because of the prominence of intelligence tests and their proxies. It is long overdue that we had more systematic ways of measuring these components of cognition, that are important in their own right, but that are missing from IQ tests. Rational thinking has a unique history grounded in philosophy and psychology, and several of its subcomponents are firmly identified with well-studied paradigms. The story we will tell in the book is of how we have turned this literature into the first comprehensive device for the assessment of rational thinking (the CART).
In fact, I think we have already entirely achieved our aims. We have a prototype test that is a pretty comprehensive measure of the rational thinking construct and that is grounded in extant work in cognitive science. Now, this is not to deny that there is still much work to be done in turning the CART into a standardized instrument that could be used for practical purposes. But of course a finished test was not our goal in this book. Our goal was to show a demonstration of concept, and we have done that. We have definitively shown that a comprehensive test of rational thinking was possible given existing work in cognitive science, which is something that I have claimed in previous books but had not empirically demonstrated with comprehensiveness that we have here by introducing the CART. As I said, there are more steps left in turning the CART into an “in the box” standardized measure, but that is a larger goal than we had for this book.
Could you say something about how the test was made and what it looks like?
The current book, and the CART itself, has been inevitable since I coined the term dysrationalia in 1993 (in a paper in the Journal of Learning Disabilities). But even an inevitable product doesn’t appear automatically, as the interim theoretical and empirical work took us over 20+ years. Our early empirical work on individual differences in rational thought (Stanovich & West, 1997, 1998, 1999) was first cashed out in terms of theoretical insights concerning dual-process theory and evolutionary psychology that were relevant to the Great Rationality Debate in cognitive science (Stanovich, 1999, 2004; Stanovich & West, 2000). The next phase of our empirical work (see Stanovich & West, 2008) led to the book that was the subject of your previous interview with me: What Intelligence Tests Miss (2009). From that book, it was clear that the next logical step was following through on our claim that there was nothing preventing the construction of a test of rational thinking. We outlined an early version of our framework for assessing rational thinking in Chapter 10 of the book Rationality and the Reflective Mind (2011). However, readers familiar with that framework will notice several quite radical changes when they read the current MIT volume. These changes resulted from the new conceptualization of heuristics and biases tasks that we offer in Chapters 3 and 4 of The Rationality Quotient.
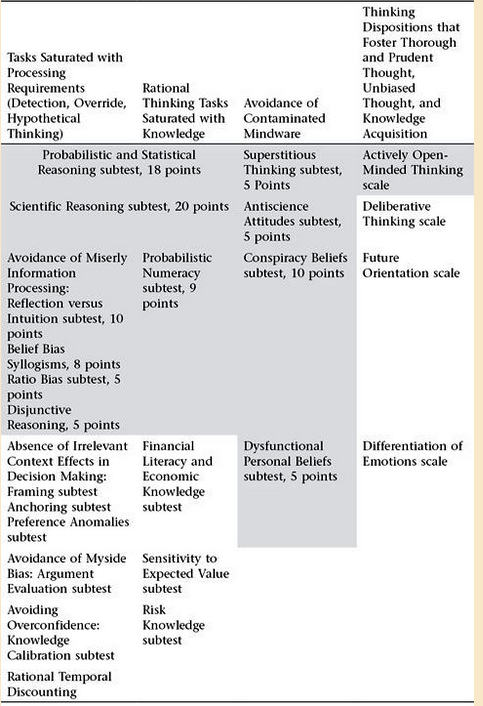
The CART has 20 subtests and four thinking dispositions scales (the latter are not part of the total score but just for informational purposes). Collectively they tap both instrumental rationality and epistemic rationality. In cognitive science, instrumental rationality means behaving in the world so that you get exactly what you most want, given the resources (physical and mental) available to you. Epistemic rationality concerns how well beliefs map onto the actual structure of the world. The two types of rationality are related. In order to take actions that fulfill our goals, we need to base those actions on beliefs that are properly calibrated to the world. Aspects of epistemic rationality that are assessed on the CART include: the tendency to show incoherent probability assessments; the tendency toward overconfidence in knowledge judgments; the tendency to ignore base rates; the tendency not to seek falsification of hypotheses; the tendency to try to explain chance events; the tendency to evaluate evidence with a myside bias; and the tendency to ignore the alternative hypothesis.
Additionally, the CART assesses aspects of instrumental rationality, such as: the ability to display disjunctive reasoning in decision making; the tendency to show inconsistent preferences because of framing effects; the tendency to substitute affect for difficult evaluations; the tendency to over-weight short-term rewards at the expense of long-term well-being; the tendency to have choices affected by vivid stimuli; and the tendency for decisions to be affected by irrelevant context.
Importantly, the test also taps what we call contaminated the mindware. This category of thinking problem arises because suboptimal thinking is potentially caused by two different types of mindware problems. Missing mindware, or mindware gaps, reflect the most common type—where Type 2 processing does not have access to adequately compiled declarative knowledge from which to synthesize a normative response to use in the override of Type 1 processing. However, in the book, we discuss how not all mindware is helpful or useful in fostering rationality. Indeed, the presence of certain kinds of mindware is often precisely the problem. We coined the category label contaminated mindware for the presence of declarative knowledge bases that foster irrational rather than rational thinking. Four of the 20 subtests assess contaminated mindware.
You have done a great deal of work to establish the psychometric properties of the CART. We lack space here to go into all the details of that but could you summarize some of your important findings?
The total CART score had a Cronbach's alpha of .86 calculated by treating subtests as items. The reliability of the 20 individual subtests varies quite a bit. The median reliability of the 20 subtests was .73. A few of the subtest reliabilities were fairly low (four were under .60). These moderate reliabilities, both of the full test and of the subtests is entirely to be expected because we have always emphasized that rationality is a multifarious construct. It is not going to result in g factor like an intelligence test. A principal components analysis of the twenty CART subtests revealed that a four component solution provided the most coherent classification of the tasks. The first principal component explained 30.7% of the variance and the first four components explained 48.6% of the variance.
The CART subtests thus have some commonality, but not the degree of commonality shown by an IQ test. Thus, the CART total score should be interpreted with caution. Rationality as a concept is multifarious, as we have argued, involving knowledge and process in complex and changing proportions across tasks and situations.
We discuss in the book that the value of the CART is independent of what future research shows its ultimate structure to be. Although of course the structure of the skills measured on the CART are important research questions, the usefulness of the rational thinking concept does not depend on there being a single-factor outcome to any structural investigation—or even a simple outcome. Rational thinking tasks will simply not cluster in the manner of intelligence tests because their underlying mental requirements are too diverse and too complex. We would not expect our rationality subscales to hang together in a particular predetermined structure because not only are there different types of mindware involved in each but also, for many of the subtests, there are different types of miserliness involved (default to Type 1 processing; serial associative cognition; override failure).
An oversimplified example will illustrate the point we wish to assert with respect to the CART. Imagine that highway safety researchers found that the following variables were causally associated with lifetime automobile accident frequency: braking skill; knowledge of the road rules; city driving skill; cornering skill; defensive driving; and a host of other relationships. In short, these skills, collectively, define a construct called “overall driver skill”. Of course we could ask these researchers whether driving skill is a g-factor or whether it is really 50 little separate skills. But the point is that the outcome of the investigation of the structure of individual differences in driving skill would have no effect on the conceptual definition of what driving skill is. It may have logistical implications for measurement, however. Skills that are highly correlated might not all have to be assessed to get a good individual difference metric. But if they were all causally related to accident frequency, they would remain part of the conceptual definition of overall driver skill. If several components or measurement paradigms turn out to be highly correlated, that will make assessment more efficient and logistically easier—but it will not enhance or diminish the status of these components as aspects of overall driving skill. It is likewise with rational thinking. There is independent evidence in the literature of cognitive science that the components of the CART form part of the conceptual definition of rational thought. Psychometric findings do not trump what cognitive scientists have found are the conceptually essential features of rational thought and action.
All of this is not to deny that it would obviously be useful to really know the structure of rational thinking skills from a psychometric point of view. Our research group has contributed to clarifying that structure. However, we want to spur efforts at assessing components of rational thought, and thus in this early stage of the endeavor we do not want the effort to be impeded by protests that the concept cannot exist because its psychometric structure is uncertain. That structure will become clarified once our call for greater attention to the measurement of this domain is heeded. We should not shy away from measuring something because of lack of knowledge of the full structure of its domain.
I make these points because in speaking and writing about the issue of measuring rational thought I am often met with what I feel is a quite baffling question that goes, roughly, as follows: “Well it’s unlikely that you’ll get a g-factor of rationality isn’t it? So how can you measure rational thinking?” The fallacy here is the idea that we can only measure things that result in tight general factors. People seem to be queasy about measuring psychological constructs that are complex and seem to want some pristine concept to arise from studies of rationality (perhaps, as we discuss in the book, because they are carrying around Aristotelian, soul-like connotations of the term rationality). We should, instead, simply get used to the fact that the concept and its measurement is bound to be multifarious and that its structure is complex.
The CART may be used for personnel selection. Could you say something about its predictive validity and about teaching to the test/fakeability?
Regarding fakeability, sixteen of the twenty subtests in the full-form CART are performance measures that cannot be faked. Only four subtests are self-report questionnaire measures (the four contaminated mindware subtests), and three of these have significant (although small) correlations with impression management/social desirability scales. [The CART contains four thinking disposition measures that are also self report, but these scales do not contribute to the CART total score because their purpose is to contextualize performance on the twenty subtests.] Any user concerned about the potential fakeability of the four contaminated mindware subtests could simply run a 16-subtest version of the CART. We show in one of the empirical chapters of the book that the 16-subtest version would capture virtually all of the variance of the full test. Such a usage would simply forgo measurement of contaminated mindware.
Regarding teaching to the test, or coachability, many of the most important dimensions of the CART—the tendency toward miserly processing, consistent decision-making, probabilistic and scientific reasoning, argument evaluation, overconfidence, etc.—are not subject to nonefficacious coaching effects. But what I mean by nonefficacious coaching effects needs to be explained, and I will do so by way of an analogy to the controversy about “teaching to the test” in education. The practice of “teaching to the test” is a bad thing when it raises test performance without truly affecting the general skills being assessed. If a teacher learns that a statewide history assessment will contain many questions on the World War II and concentrates on that during class time to the exclusion of other important topics, then the teacher has perhaps increased the probability of a good score on this particular test, but has not facilitated more general historical knowledge. This is nonefficacious coaching.
But in education, not all coaching in anticipation of assessments is of this type. Early reading skills provide the contrast to assessments of history knowledge. Imagine that teachers knew of the appearance of subtests measuring word decoding skills (letter-sound knowledge and phonemic awareness) on a statewide early reading test and “taught to” that test. In this case, the teachers would in fact be teaching the key generalizable skills of early reading. They would be teaching the most fundamental processes underpinning reading development. This would be efficacious “teaching to the test”.
The point here is that the coachability of a skill does not necessarily undermine the rationale for including the skill in an assessment. To put it colloquially, some “coaching” is little more than providing “tricks” that lift assessment scores without really changing the underlying skill, whereas other types of coaching result in changes in the underlying skill itself. There is no reason to consider the latter type of coaching a bad thing and thus no reason to consider an assessment domain to be necessarily problematic because it is coachable. Thus, it is important to realize that many rational thinking domains may be of the latter type—that is, amenable to what we might call virtuous coaching. If a person has been “coached” to always see the relevance of baserates, to always explore all of the disjunctive decision possibilities, to routinely reframe decisions, to consider sample size, to see event spaces, and to see the relevance of probabilistic thinking—then one has increased rational thinking skills and tendencies. As I mentioned previously, I agree that coaching people on what is considered the proper response to the four contaminated mindware subtests would be easy and would represent inefficacious coaching. But most of the rest of the CART (the 16 other subtests) is not subject to easy and inefficacious coaching of this type.
How may the CART be useful for educational purposes? For example, might your conceptual framework be directly used for designing a curriculum?
To continue the point from the previous question, if the existence of rational thinking assessment devices such as the CART spawns such teaching to the test, then this can be nothing but a good thing for society. And yes, I feel that our framework would be useful for educational purposes. The main reason is that our framework provides a mix of process considerations and knowledge considerations. Critical thinking assessment, for example, is often criticized for its over-emphasis on process issues and for its failure to acknowledge that no thinking can be rational or critical without requisite knowledge. In contrast, the CART assesses critical knowledge bases (numeracy, financial literacy, risk knowledge) while also measuring the tendency to acquire problematic knowledge (superstitions, anti-science attitudes, conspiracy theories). Of course, the CART also assesses processing issues related to rationality under the general rubric of miserly information processing. In spanning both knowledge and process issues, the CART provides a more comprehensive framework for educational applications than have previous attempts to facilitate thinking and reasoning.
What are your plans and hopes for the near future regarding the CART and rational thinking?
We believe that as a research instrument, the CART is currently the premiere research measure of rational thinking, comprehensively assessed. From that standpoint, we feel that we have already reached our main goal. For practical use, as an assessment and selection device, it is more a proof of concept. For that purpose, it will need more development because it is not at present a fully developed test for practical use (with things like norms and percentiles). Nevertheless, the CART, as it exists, is the beta version of a very comprehensive test that will be a fantastic research instrument. Future work will take it beyond that point.
One future use will undoubtedly be universities who will be interested in standardized versions of the CART so that they might assess whether their educational programs are increasing the rationality of students over time. That is, we fully expect a more well-developed version of the CART to take its place alongside other measures that universities have used to operationalize the real-life effects of a college education on cognition and learning (universities already use several critical thinking tests and assessment devices like the Collegiate Learning Assessment). The use of such a test near or at the end of university training would provide an assessment of whether students have acquired a functional understanding of the tools of rationality that have been described in our volume.
As I mentioned, my aim in my earlier book, What Intelligence Tests Miss, was to suggest that in theory we could begin to assess rationality as systematically as we do IQ. The existence of the CART follows through on this claim. Whereas just thirty years ago we knew vastly more about intelligence than we knew about rational thinking, this imbalance has been redressed in the last few decades because of some remarkable work in behavioral decision theory, cognitive science, and related areas of psychology. In the past two decades cognitive scientists have developed laboratory tasks and real-life performance indicators of myriad rational thinking indicators. With the CART, we have transformed this work into the first comprehensive assessment measure for rational thinking, the CART.
***
References
- Stanovich, K. E. (1993). Dysrationalia: A new specific learning disability. Journal of Learning Disabilities, 26, 501-515.
- Stanovich, K. E. (1999). Who is rational? Studies of individual differences in reasoning. Mahwah, NJ: Erlbaum.
- Stanovich, K. E. (2004). The robot's rebellion: Finding meaning in the age of Darwin. Chicago: University of Chicago Press.
- Stanovich, K. E. (2009). What intelligence tests miss: The psychology of rational thought. New Haven, CT: Yale University Press.
- Stanovich, K.E. (2011). Rationality and the Reflective Mind. New York: Oxford University Press.
- Stanovich, K. E., & West, R. F. (1997). Reasoning independently of prior belief and individual differences in actively open-minded thinking. Journal of Educational Psychology, 89, 342-357.
- Stanovich, K. E., & West, R. F. (1998). Individual differences in rational thought. Journal of Experimental Psychology: General, 127, 161-188.
- Stanovich, K. E., & West, R. F. (1999). Discrepancies between normative and descriptive models of decision making and the understanding/acceptance principle. Cognitive Psychology, 38, 349-385.
- Stanovich, K. E., & West, R. F. (2000). Individual differences in reasoning: implications for the rationality debate? Behavioral and Brain Sciences, 23, 645-665.
- Stanovich, K. E., & West, R. F. (2008). On the relative independence of thinking biases and cognitive ability. Journal of Personality and Social Psychology, 94, 672-695.
- Visser, C.F. (2009). Interview with Keith Stanovich. http://www.progressfocused.com/2009/11/interview-with-keith-stanovich.html
Comments